pRPC 零拷贝高性能网络通信协议
pRPC 零拷贝高性能网络通信协议 贡献者: 第四范式 许可证:Apache License 2.0
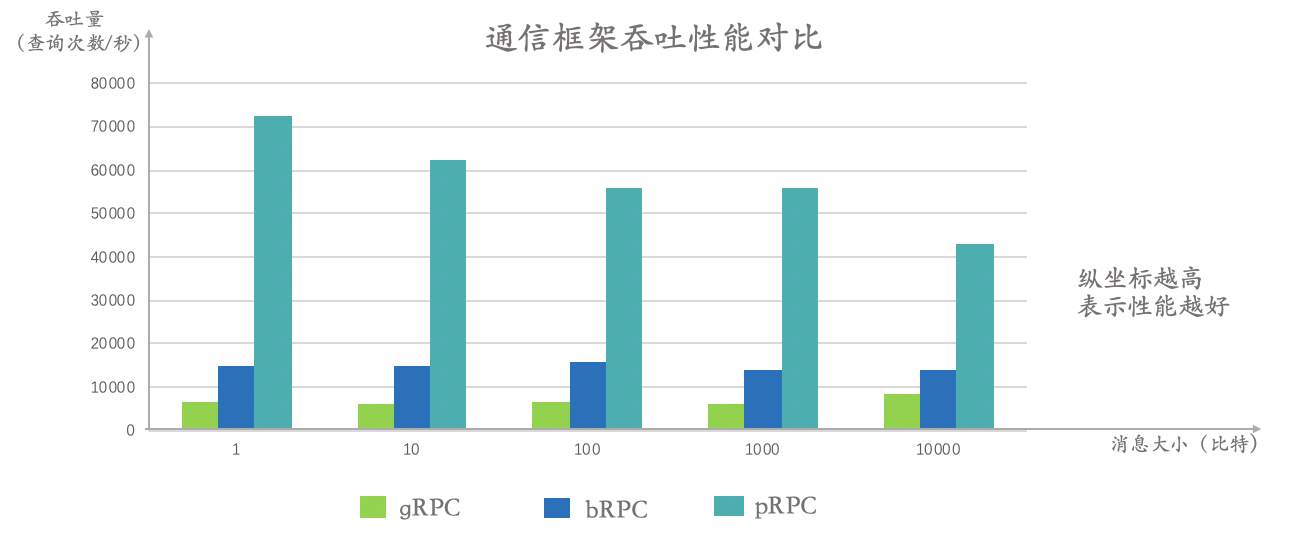
pRPC 面向AI模型训练中大规模的数据和参数移动负载特性进行优化,相比百度bRPC、Google gRPC等通用网络通信框架,实现高达10倍的网络通信性能提升。
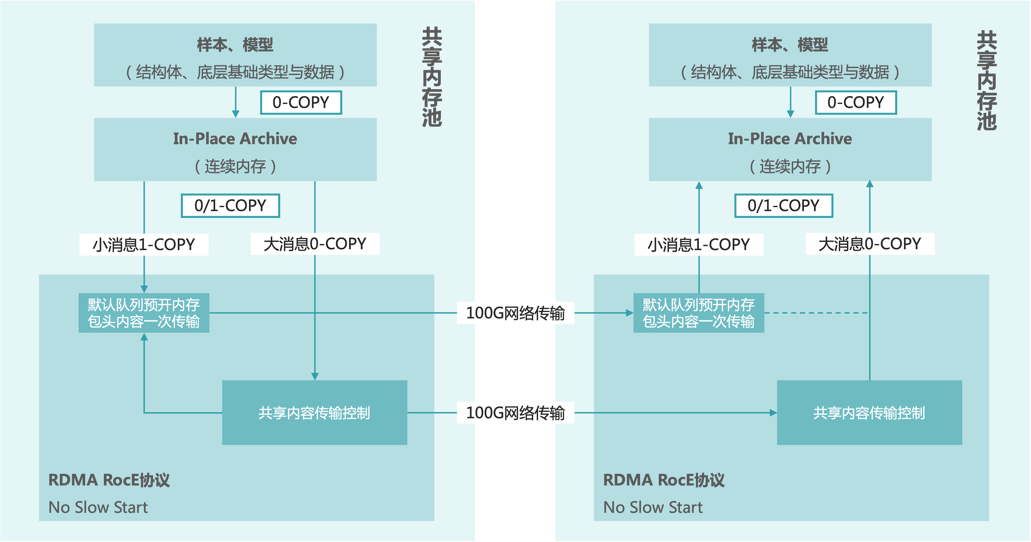
pRPC是一个面向机器学习工作负载的高性能网络通信框架,通过内存零拷贝设计实现更快的网络通信、以及更高的数据移动吞吐,针对机器学习工作负载中梯度计算、参数同步等环节的突发流量,在保障线程安全的情况下,提供消息级负载均衡,支持结合100G+RDMA远程直接内存访问技术,实现序列化与反序列化中的高效处理,突破TCP的性能瓶颈,最大化分布式计算性能,解决机器学习分布式训练中的网络瓶颈。
不同类型的AI算法在训练过程中面临不同的网络性能瓶颈,消息吞吐量制约处理大规模离散特征的算法(如LR等)的训练性能,网络延迟制约处理稠密特征的算法(如深度学习算法或者树模型等)。
无锁排队与批量消息处理的线程安全技术,减少线程跳转与缓存同步
支持RDMA,绕过TCP,解决slow start的问题;RDMA实现网卡对内存的访问,直接发挥硬件的最大价值
应用层内存共享技术,减少数据在内存、网卡间、客户端与服务端间的冗余拷贝
pRPC架构
pRPC 面向AI模型训练中大规模的数据和参数移动负载特性进行优化,相比百度bRPC、Google gRPC等通用网络通信框架,实现高达10倍的网络通信性能提升。