近期,OpenI启智社区召集了技术委员会成员针对社区重点项目进入孵化培育管道的评审决策会议,最终共计通过2个重点开源项目的贡献申请,分别是来自鹏城实验室开源所贡献的鹏程·盘古α项目与来自智源语言大模型加速技术创新中心贡献的OpenBMB项目。
恭喜这2个项目正式进入启智社区开源项目孵化管道,它们丰富了OpenI启智社区在模型储备方面的内容,进一步完善社区总体技术架构。
PanGu-α
2000亿参数中文自回归大模型
贡献者:鹏城实验室
许可证:Apache License 2.0
项目地址:https://git.openi.org.cn/PCL-Platform.Intelligence
鹏程·盘古α是业界首个2000亿参数以中文为核心的预训练生成语言模型,目前开源了两个版本:鹏程·盘古α和鹏程·盘古α增强版,并支持NPU和GPU两个版本,支持丰富的场景应用,在知识问答、知识检索、知识推理、阅读理解等文本生成领域表现突出,具备较强的少样本学习的能力。例如:
Input: 中国和美国和日本和法国和加拿大和澳大利亚的首都分别是哪里? Generate: 中国的首都是北京,美国的首都是华盛顿,日本的首都是东京,法国的首都是巴黎,澳大利亚的首都是堪培
基于盘古系列大模型提供大模型应用落地技术帮助用户高效的落地超大预训练模型到实际场景。
整个框架特点如下:
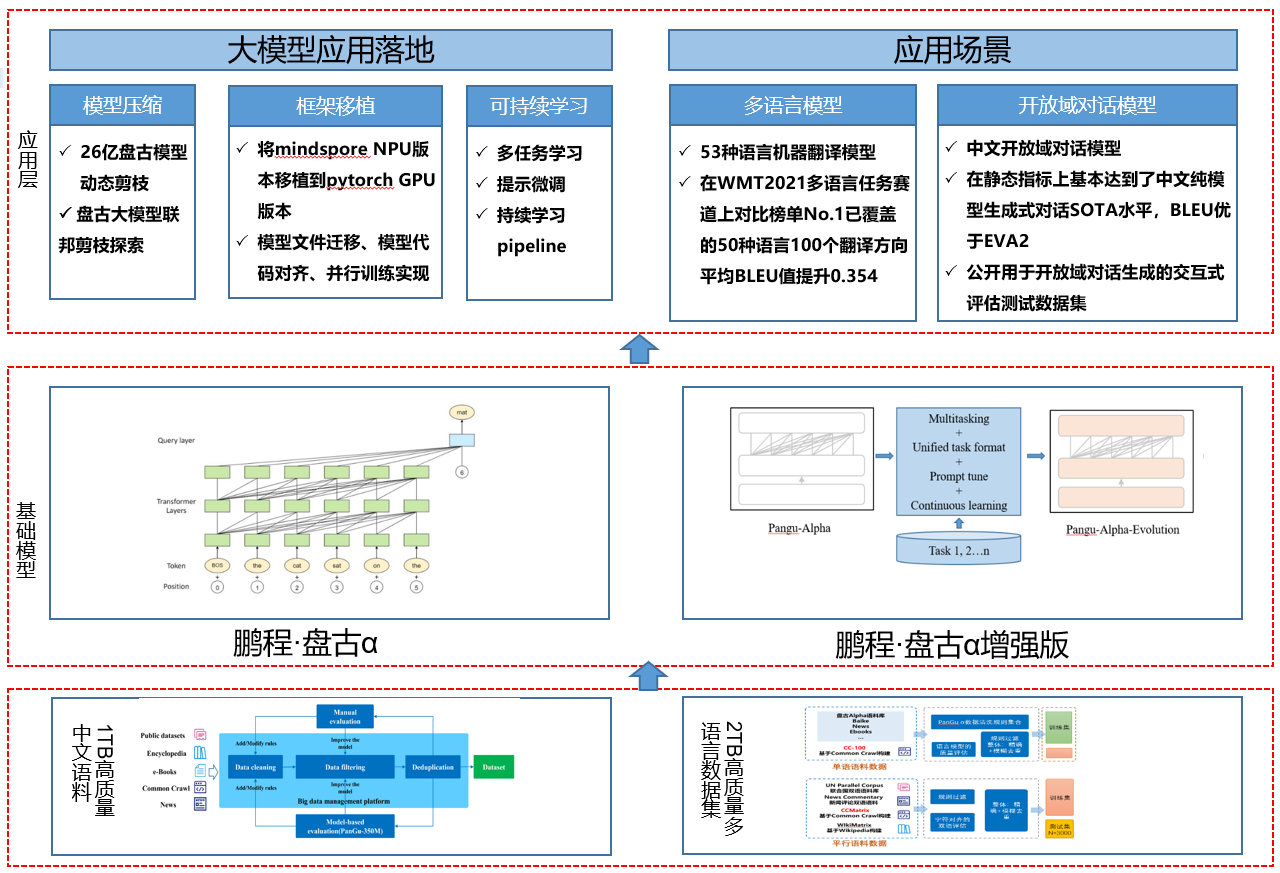
主要有如下几个核心模块:
数据集:从开源开放数据集、common crawl数据集、电子书等收集近80TB原始语料,构建了约1.1TB的高质量中文语料数据集、53种语种高质量单、双语数据集2TB。
基础模块:提供预训练模型库,支持常用的中文预训练模型,包括鹏程·盘古α、鹏程·盘古α增强版等。
应用层:支持常见的NLP应用比如多语言翻译、开放域对话等,支持预训练模型落地工具,包括模型压缩、框架移植、可持续学习,助力大模型快速落地。
正在进行的开源工作有:
应用组件:为快速适配用户的应用场景,将推出基于盘古大模型的一系列组件,如微调、压缩、框架迁移等,实现一键式微调和模型迁移功能。
云服务提供:结合智算网络提供模型训练、微调、压缩等开源应用创新的算力支持,优化基础大模型的云服务能力,支持本地调用的同时,也可以在云上实现调用,给用户带来高效的从训练到落地的完整体验。
盘古α项目已在OpenI启智社区实现了数据、算法、模型和服务的逐步全面开源开放,希望以OpenI启智开源社区为载体,集众智、聚众力,吸引开发者共同参与到模型的压缩轻量化和应用创新工作中,不断探索“盘古α”模型的强大潜力。

Open Lab for Big Model Base
大规模预训练语言模型库与相关工具
贡献者:清华大学、北京智源人工智能研究院语言大模型加速技术创新中心、ModelBest
许可证:Apache License 2.0
项目地址:https://git.openi.org.cn/OpenBMB
OpenBMB全称为Open Lab for Big Model Base,旨在打造大规模预训练语言模型库与相关工具,加速百亿级以上大模型的训练、微调与推理,降低大模型使用门槛,与国内外开发者共同努力形成大模型开源社区,推动大模型生态发展,实现大模型的标准化、普及化和实用化,让大模型飞入千家万户。
OpenBMB将努力建设大模型开源社区,团结广大开发者不断完善大模型从训练、微调、推理到应用的全流程配套工具。
基于贡献者团队前期工作,OpenBMB设计了大模型全流程研发框架,并初步开发了相关工具,这些工具各司其职、相互协作,共同实现大模型从训练、微调到推理的全流程高效计算。
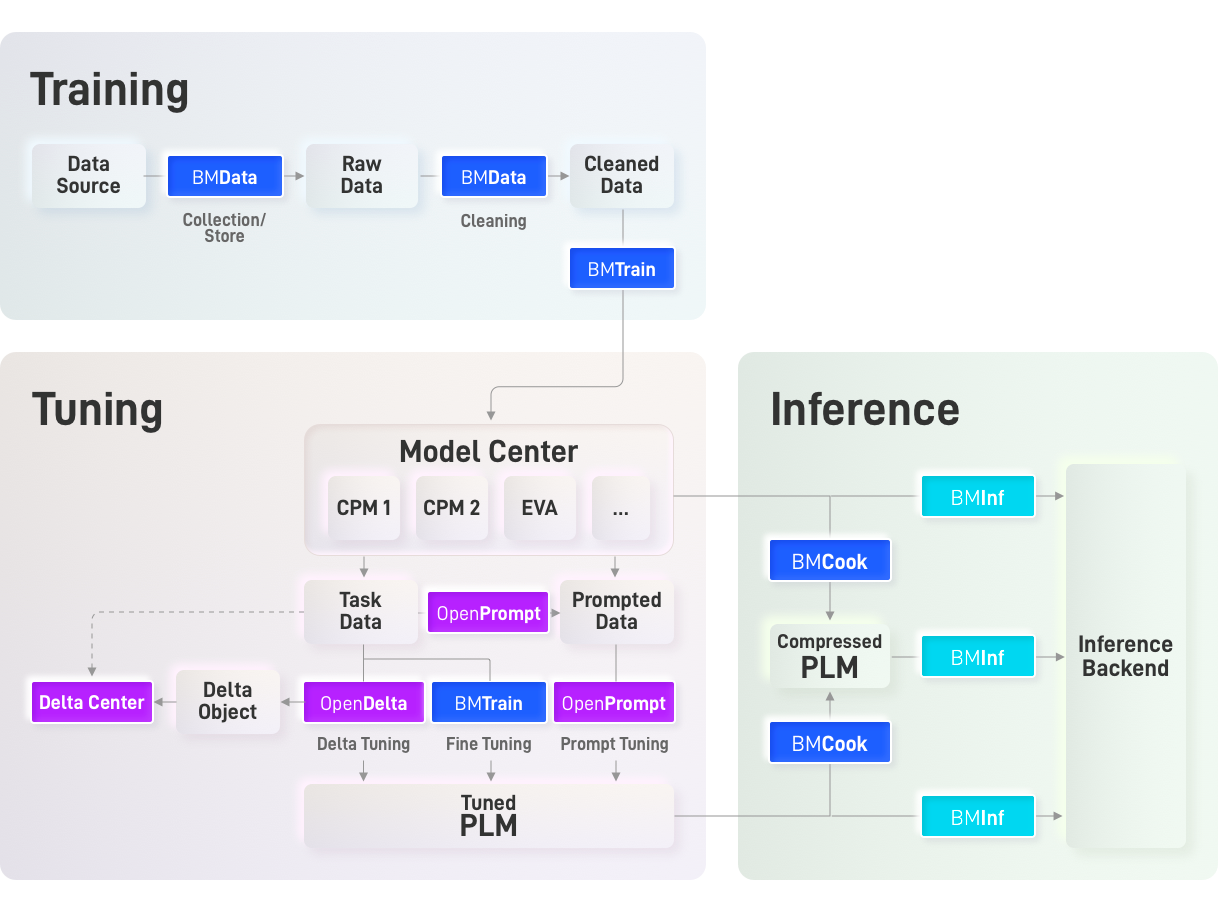
OpenBMB开源社区推崇简洁,追求极致,相信数据与模型的力量。欢迎志同道合的开发者们加入,共同为大模型应用落地添砖加瓦,早日让大模型飞入千家万户。
OpenI启智社区从服务新一代人工智能重大科技项目出发,为我国的新一代人工智能发现项目、培育项目、检验项目和推广项目。目前,社区已孵化33个重点开源项目,形成包含基础设施、软件环境、算法框架、模型储备、应用开发部署的多维度、全流程的社区开源技术体系。
社区坚持以开放的心态与国内外的社区、项目合作,也在“尊重创新”的原则下, 欢迎有志于AI开源事业的开发者加入社区,共同促进AI开源开放生态体系建设。如有意贡献项目和参与社区孵化培育的个人或组织,请参考《启智社区项目开源指南》提供项目相关材料。