零售行业是我国非常重要的行业之一,随着手机支付和购物用户数量的不断提高,以及数字化技术的不断发展,零售行业的企业尤其是线下体验店对数字化转型的意愿不断加强,未来我国智慧零售行业有望持续快速发展。
那么,零售行业有哪些痛点?人工智能在零售行业又能有哪些技术突破和创新呢?
今天,OpenI要为大家介绍社区最新入驻且正进入社区孵化管道的零售行业开源项目【袋鼯麻麻ColugoMum】,该项目由一群优秀的本科生组成的ColugoMum团队,基于国产深度学习开源框架飞桨PaddlePadddle开发,针对中小型线下零售体验店提供了一系列解决方案。
项目开源地址:
目前在零售行业的实际运营过程中,会产生巨大的人力成本,例如导购、保洁、结算等,而其中,尤其需要花费大量的人力成本和时间成本在识别商品并对其进行价格结算的过程中,并且在此过程中,顾客也因此而需要排队等待。这样一来零售行业人力成本较大、工作效率极低,二来也使得顾客的购物体验下降。

随着计算机视觉技术的发展,以及无人化、自动化超市运营理念的提出,利用图像识别技术及目标检测技术实现产品的自动识别及自动化结算的需求呼之欲出,即自动结账系统(Automatic checkout, ACO)。
基于计算机视觉的自动结账系统能有效降低零售行业的运营成本,提高顾客结账效率,从而进一步提升用户在购物过程中的体验感与幸福感。
AI结算的核心是图像识别。图像识别的准确率决定了AI结算落地的可行性。目前,AI结算面临着如下几个痛点问题:
商品包装相似:同类别商品口味不同且价格也不同,不同类别商品外包装相似,都对图像识别精度具有较高的要求;
干扰因素众多:同类别商品在识别时容易因角度问题发生变形、折叠、遮挡等干扰,对识别结果造成影响;
品类更新极快:零售商品通常以小时级别速度更新迭代,每增加新产品时若仅靠单一模型均需重新训练模型,模型训练成本及时间成本极大;
系统性能要求高:需要同时解决检测和识别两个任务,选模型和优化时要权衡精度与速度两方面。
袋鼯麻麻ColugoMum致力于为中小型线下零售体验店提供基于视觉的零售结算方案。

基于上述痛点问题,ColugoMum团队采用飞桨PaddleClas[1]团队提出的PP-ShiTu[2]图像识别系统。
基于PP-ShiTu实现的商品识别方案为零售场景中商品多类别、小样本、高相似和更新频繁问题提供了新的思路,不仅能对多类别商品进行精准识别,也可以满足对预测效率的极致追求。
尤为实用的功能在于:实际上线使用的时候,遇到新的需要识别的商品类别,无需重新训练模型,只需要在检索库中增加该类别图像特征,就能够实现对新商品的识别!
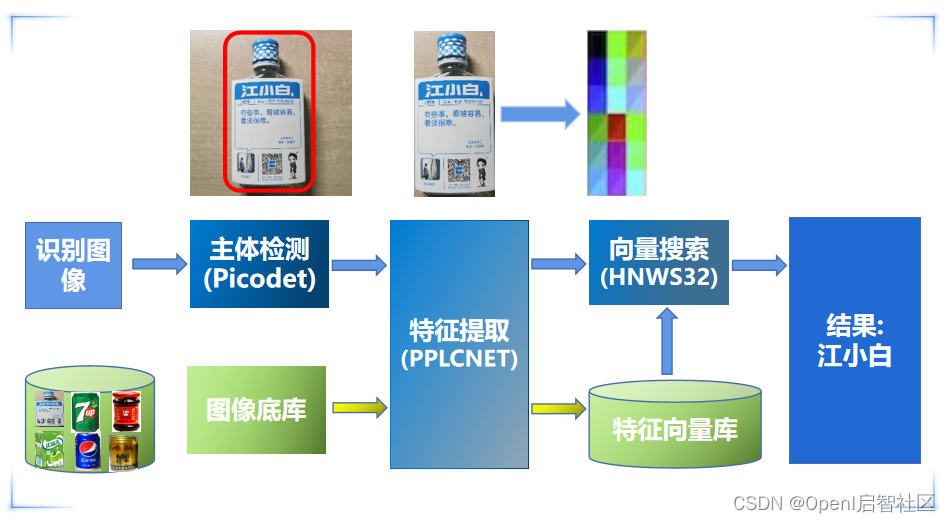
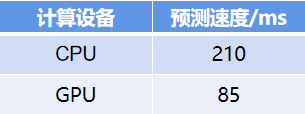
PP-ShiTu是一个实用的轻量级通用图像识别系统,主要由主体检测、特征学习和向量检索三个模块组成。该系统从骨干网络选择和调整、损失函数的选择、数据增强、学习率变换策略、正则化参数选择、预训练模型使用以及模型裁剪量化8个方面,采用多种策略,对各个模块的模型进行优化,并经过10w+类别数据进行训练,最终得到在CPU上预测时间仅需0.2s的多场景通用图像识别系统。
简单来说,PP-ShiTu的使用分为三步:
通过主体检测模型,对图片中的物体一一识别;
对每个候选区域进行特征提取;
将特征提取后的向量在检索库中进行检索,完成匹配,返回识别结果。
考虑到实际零售场景对于精度和预测速度的极致追求,ColugoMum团队在主体检测部分选取了PicoDet模型作为主体检测算法,选取了轻量级PPLCNet_x2_5_ssld模型用作特征提取,最后使用向量搜索模块Faiss中的HNSW32作为检索算法,实现速度与精度的极致平衡。
基于此,ColugoMum团队基于RP2K数据集已经实现了最高96.91%的预测精度。
RP2K数据集[3]:收录了50万+张零售商品货架图片,商品种类超过2,000种,是目前零售类数据集中产品种类数量最多的数据集。不同于一般聚焦新产品的数据集,RP2K收录了超过50万张零售商品货架图片,商品种类超过2000种,该数据集是目前零售类数据集中产品种类数量TOP1,同时所有图片均来自于真实场景下的人工采集,针对每种商品,品览提供了十分详细的标注。
此外,ColugoMum也收集整理了业内SKU级别的商品图像数据集,并期待和开发者们一道, 开源出能够在业内有影响力、符合实际场景应用需求的数据集。
数据集地址:
并且,ColugoMum团队开源了基于RP2K数据集的高精度训练模型和预测模型。开发者可以在提供的训练模型上基于自己的数据进行微调,也可以使用提供的预测模型直接进行预测体验。同时,ColugoMum也开启了基于RP2K的打榜活动,欢迎开发者们参与。
地址:
部署方面使用飞桨服务化部署框架Paddle Serving[4]进行部署,满足用户批量预测、数据安全性高、延迟低的需求,在CPU上仅需0.2秒即可实现预测效果,真正做到预测速度与精度的极致平衡。
为了方便开发者们更好地理解PP-ShiTu、更好地利用其在图像识别领域的优势,ColugoMum团队开源了基于图像识别的智慧零售商品识别教程,开发者可以在此基础上使用PP-ShiTu快速对接业务。
教程地址:
基于上述核心技术,目前ColugoMum团队利用PP-ShiTu技术,开源了云边一体、符合实际场景应用需求的商品识别Smart_container。其能够精准地定位顾客购买的商品,并进行智能化、自动化的价格结算。
项目地址:
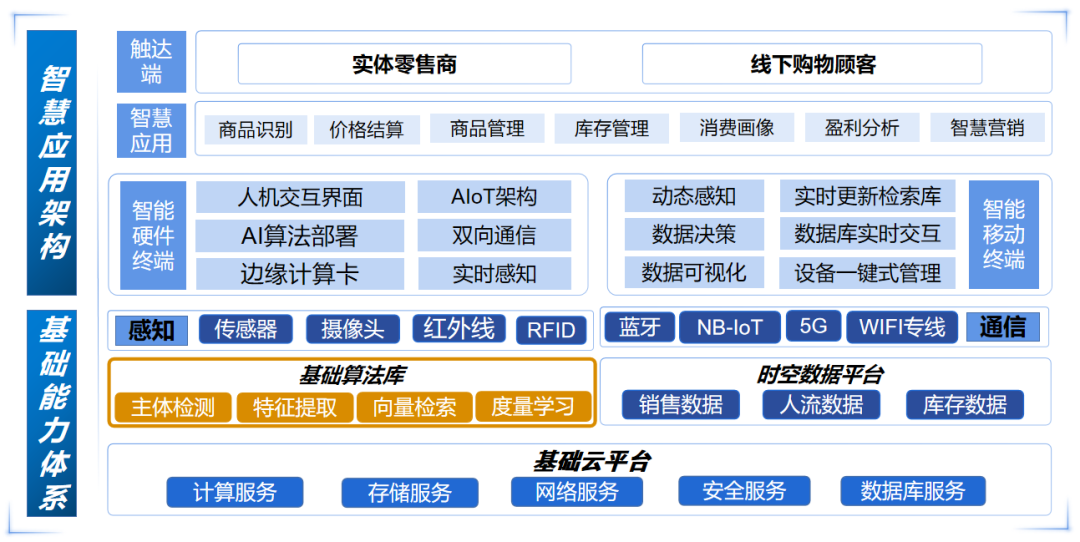
当顾客将自己选购的商品放置在制定区域内时,Smart_container能够精准地定位识别每一个商品,并且能够返回完整的购物清单及顾客应付的实际商品总价格。而当系统有新商品增加时,只需更新检索库即可,无需重新训练模型。
Smart_container覆盖硬件结算台、小程序管理平台、大数据可视化平台,实现了多端统一,智慧管理。


颜鑫
华东理工大学自动化专业大三在读,研究方向为多机器人的协同控制与决策,主要兴趣点为计算机视觉、强化学习、推理部署。飞桨开发者技术专家、Datawhale成员、华为云享专家、国家级大学生创新创业项目第一主持人,曾获第十三届“挑战杯”大学生创业计划竞赛上海市铜奖、华东理工大学第十届“奋进杯”大学生创业计划竞赛金奖、PPSIG优秀开源项目奖等。
颜鑫的开发心得
很荣幸能够有这样的机会,我们能在启智社区分享团队针对“AI+实体零售”的一些想法和一些成果。
在项目的实际开发过程中,团队曾面临着非常多的困难,比如缺乏一个稳定的协同开发环境导致开发效率极低、模型训练需要大量的计算资源导致我们一度陷入困境。
好在启智社区为我们提供了鹏城实验室的鹏城云脑1计算资源,这不仅大大减少了我们在硬件方面的投入成本,更是完美解决了我们在开发环境不完善和计算资源不充足等方面的瓶颈,才使ColugoMum项目的开发周期得以极大缩短。
此外,由于当前国际形式的强烈不稳定性,ColugoMum在框架选择上选取了国产深度学习开源框架飞桨PaddlePaddle,在开发过程中也受到了来自飞桨PaddleClas团队的大力支持,也期待国产深度学习开源框架能越来越好。
后面ColugoMum团队会不断打破产品和技术边界,依托启智社区,开源出更多更好的、能真正赋能实体零售的开源项目,真正推动我国实体零售向智能化、数字化转型,也期待众多开发者能加入我们。
沈晨
华东理工大学信息工程专业大三在读,曾获得CRAIC中国机器人及人工智能大赛上海市二等奖、上海市大学生计算机应用能力设计大赛上海市二等奖,华东理工大学第十届“奋进杯”大学生创业计划竞赛金奖,参与多个大型优秀开源项目,拥有软件著作权两篇,曾在IEEE国际会议发表论文一篇,另有一项实用新型专利正在受理。曾任信息学院团委组织部副部长,获得校优秀奖学金和优秀学生先进称号。
沈晨的开发心得
很高兴能得到在启智社区分享我们团队项目的机会,这能让更多人看到我们团队的努力成果,是ColugoMum项目的一次机遇,同时本人也很荣幸能参与ColugoMum项目的开发工作。
在项目开发过程中,我得到了很多学习和成长的机会,不管是在项目初期的程序开发阶段还是在目前的交流成长阶段,同团队成员一起精心打磨项目的过程虽然辛苦,但却是对自己的挑战与要求,并且与团队成员一起努力和成长本身就是一件快乐的事情,这让我受益匪浅。
与此同时,启智社区和飞桨PaddleClas团队也给予了我们团队莫大的支持和帮助,这让我们能够花更少的时间去寻求资源,转而精心打磨项目。
未来,我也将和团队成员一起,推动ColugoMum项目走向更广阔的沃土,为推动实体零售的智能化、数字化做出自己的努力。
杜旭东
华东理工大学信息工程专业大三在读,熟练掌握C/C++/Python/Jave/Matlab/verilog等多种编程语言,上海市大学生计算机应用能力设计大赛上海市二等奖,参与多个大型优秀开源项目,拥有软件著作权两篇,一项实用新型专利正在受理。曾任信息学院社团管理部副部长,获得校优秀奖学金。
此外,团队也向曾参与项目研发的同学表示感谢:黄小悦、王鑫、赵祎安、周天奕、申佳川等。
面对当前国际形式的强烈不稳定因素,ColugoMum团队认为国产的深度学习框架以及本土的托管平台在当前形式下更加稳妥。因此,在项目推进过程中,除了选用国产深度学习开源框架飞桨PaddlePadddle之外,团队也受到了来自OpenI启智社区的强力支持。基于启智社区中AI协作平台的协同开发能力、丰富的计算资源以及强有力的资源对接能力等,团队能够更快更高效地开展实验、推进项目,大大缩短开发周期,推动AI在实体零售行业的真正落地应用。
最后,OpenI启智社区欢迎更多开发者共同参与零售商品识别数据集、商品识别打榜以及Smart Container的开源共建活动,推动我国实体零售向数字化、智能化方向转型发展,真正实现ColugoMum“降本增效、赋能零售”的使命。
同时,社区也欢迎更多优秀的项目入驻OpenI进行开源开放,社区将提供平台资源和激励机制帮助项目孵化发展和开发者培育,共同促进AI开源开放生态体系建设。
参考文献
1.https://github.com/PaddlePaddle/PaddleClas
2. S. Wei et al., "PP-ShiTu: A Practical Lightweight Image Recognition System," arXiv preprint arXiv:2111.00775, 2021.
3. J. Peng, C. Xiao, and Y. Li, "RP2K: A large-scale retail product dataset for fine-grained image classification," arXiv preprint arXiv:2006.12634, 2020.
4.https://github.com/PaddlePaddle/Serving