近年来,随着预训练语言模型技术引发人工智能领域性能革命,大规模预训练模型技术的成熟标志着“大模型时代”的到来。然而在大模型的具体应用与落地中,却存在着“训练难、微调难、应用难”三大挑战。
为此,清华大学自然语言处理实验室和智源研究院语言大模型加速技术创新中心共同支持发起了OpenBMB(Open Lab for Big Model Base)开源社区,旨在打造大规模预训练语言模型库与相关工具,加速百亿级以上大模型的训练、微调与推理,降低大模型使用门槛,实现大模型的标准化、普及化和实用化。
为了让大模型飞入千家万户,OpenBMB开源社区、鹏城实验室,以及OpenI启智社区已携手进行国内独家开源合作,将共同推动大模型在人工智能开源领域的发展与普及。目前,OpenBMB社区已正式入驻并将其部分模型套件开源部署至OpenI启智社区,计划通过OpenI启智社区进行代码和数据集的开放管理,汇聚更多开源开发者的力量,以及基于鹏城云脑科学装置提供的算力资源,进一步推进OpenBMB系列大模型套件的开发与训练。
欢迎大家访问OpenBMB开源社区主页链接,参与代码贡献与支持社区建设。
https://git.openi.org.cn/OpenBMB
近年来人工智能和深度学习技术飞速发展,极大改变了我们的日常工作与生活。伴随人类社会信息化产生海量数据,人工智能技术能够有效学习数据的分布与特征,对数据进行深入分析并完成复杂智能任务,产生巨大的经济与社会价值,人类社会步入了“大数据时代”。
当前人工智能算法的典型流程为:准备数据、训练模型和部署模型。其挑战在于,针对给定任务人工标注训练数据注费时费力,数据规模往往有限,需要承担算法性能不达标、模型泛化能力差等诸多风险,导致人工智能面临研发周期长、风险大、投入成本高的困局,阻碍了人工智能算法的落地与推广。
2018年预训练语言模型技术横空出世,形成了“预训练-微调”的新研发范式,极大地改变了上述困局。在这个新范式下,我们可以非常容易地搜集大规模无标注语料,采用自监督学习技术预训练语言模型;然后可以利用特定下游任务对应的训练数据,进一步微调更新模型参数,让该模型掌握完成下游任务的能力。大量研究结果证明,预训练语言模型能够在自然语言处理等领域的广大下游任务上取得巨大的性能提升,并快速成长为人工智能生态中的基础设施。
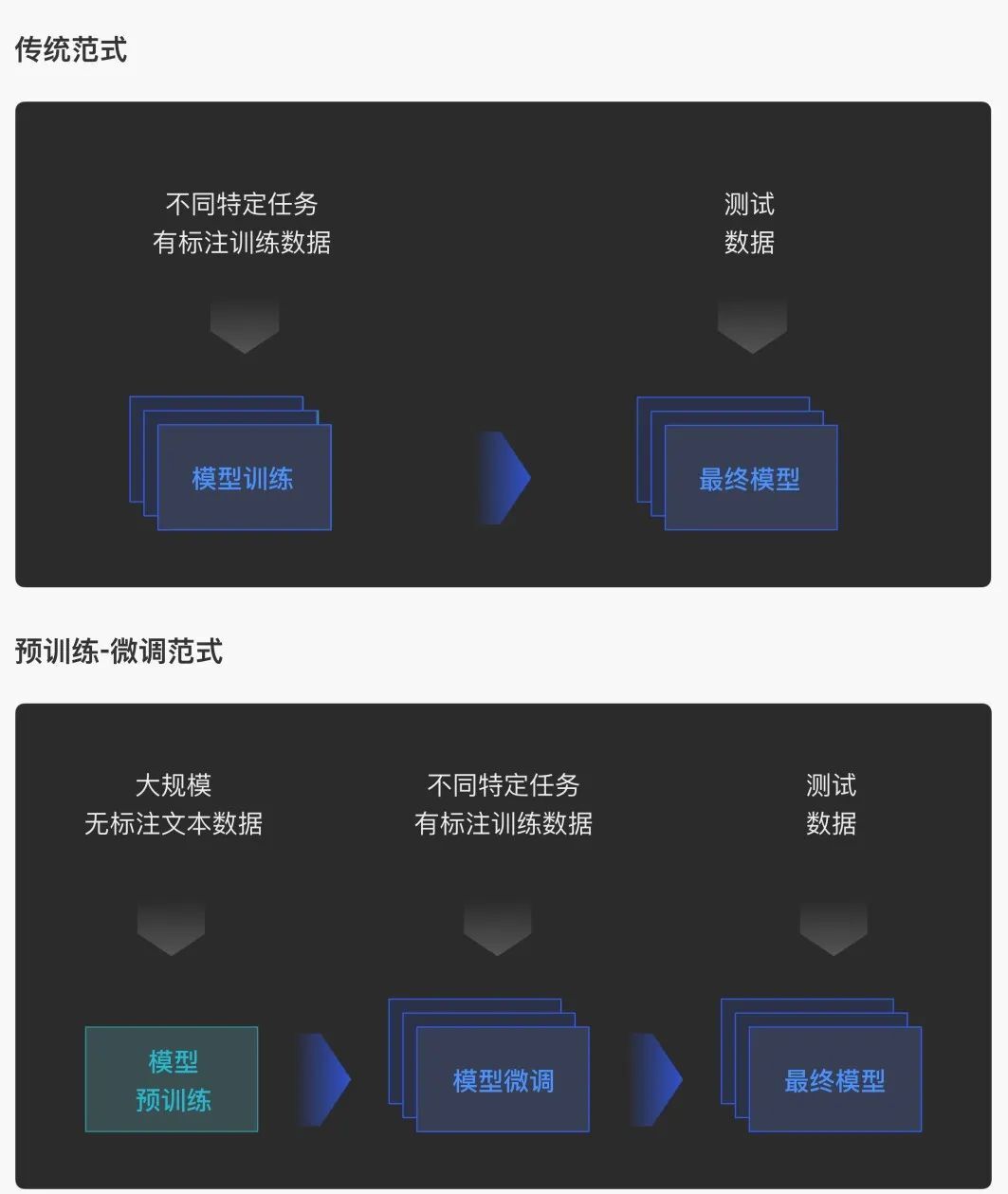
预训练 - 微调范式对比传统范式
通过充分利用互联网上近乎无穷的海量数据,预训练模型正在引发一场人工智能的性能革命。研究表明,更大的参数规模为模型性能带来质的飞跃。对十亿、百亿乃至千亿级超大模型的探索成为业界的热门话题,引发国内外著名互联网企业和研究机构的激烈竞争,将模型规模和性能不断推向新的高度。除Google、OpenAI等国外知名机构外,近年来国内相关研究机构与公司也异军突起,形成了大模型的研究与应用热潮。围绕大模型展开的"军备竞赛"日益白热化,成为对海量数据、并行计算、模型学习和任务适配能力的全方位考验,人工智能进入“大模型时代”。
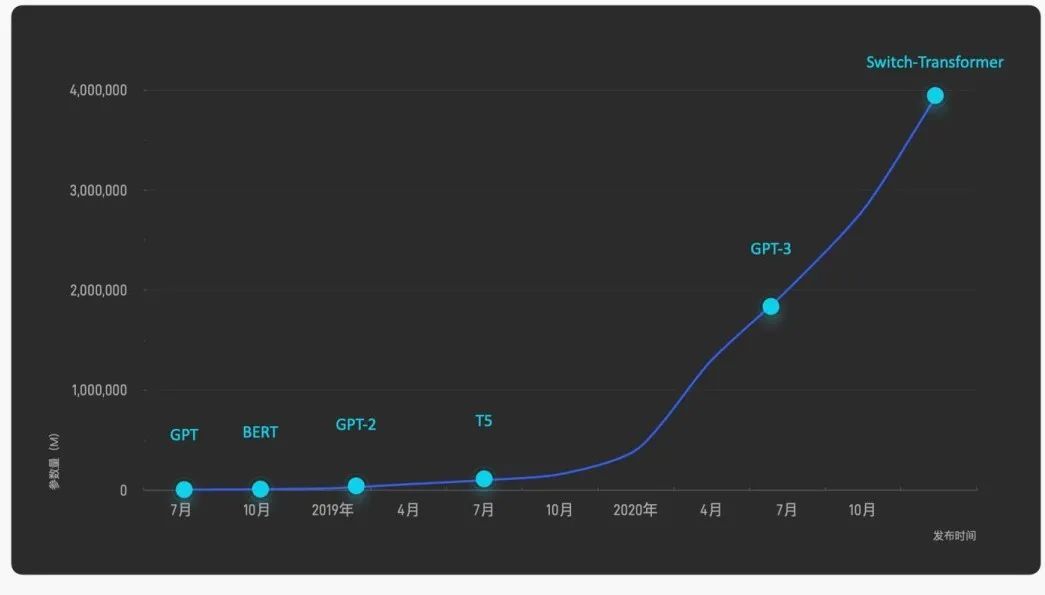
国内外知名机构在大模型训练中持续投入
然而在“大模型时代”,因为大模型巨大的参数量和算力需求,在大范围内应用大模型仍然存在着较大的挑战。如何让更多开发者方便享用大模型,如何让更多企业广泛应用大模型,让大模型不再“大”不可及,是实现大模型可持续发展的关键。与普通规模的深度学习模型相比,大模型训练与应用需要重点突破三大挑战:
▶ 训练难:训练数据量大,算力成本高。
▶ 微调难:微调参数量大,微调时间长。
▶ 应用难:推理速度慢,响应时间长,难以满足线上业务需求。
为了让大模型技术更好地普及应用,针对这些挑战,清华大学自然语言处理实验室和智源研究院语言大模型加速技术创新中心成立了OpenBMB开源社区。
谋定而动,OpenBMB将从数据、工具、模型、协议四个层面构建应用便捷、能力全面、使用规范的大规模预训练模型库。

OpenBMB 能力体系
OpenBMB能力体系具体包括:
• 数据层:构建大规模数据自动收集、自动清洗、高效存储模块与相关工具,为大模型训练提供数据支持。
• 工具层:聚焦模型训练、模型微调、模型推理、模型应用四个大模型主要场景,推出配套开源工具包,提升各环节效率,降低计算和人力成本。
• 模型层:构建OpenBMB工具支持的开源大模型库,包括BERT、GPT、T5等通用大模型和CPM、EVA、GLM等悟道开源大模型,并不断完善添加新模型,形成覆盖全面的模型能力。
• 协议层:发布通用模型许可协议,规范与保护大模型发布使用过程中发布者与使用者权利与义务,目前协议初稿已经开源(https://www.openbmb.org/license)。
大模型相关工具在OpenBMB能力体系中发挥着核心作用。OpenBMB将努力建设大模型开源社区,团结广大开发者不断完善大模型从训练、微调、推理到应用的全流程配套工具。基于发起人团队前期工作,OpenBMB设计了大模型全流程研发框架,并初步开发了相关工具,这些工具各司其职、相互协作,共同实现大模型从训练、微调到推理的全流程高效计算。
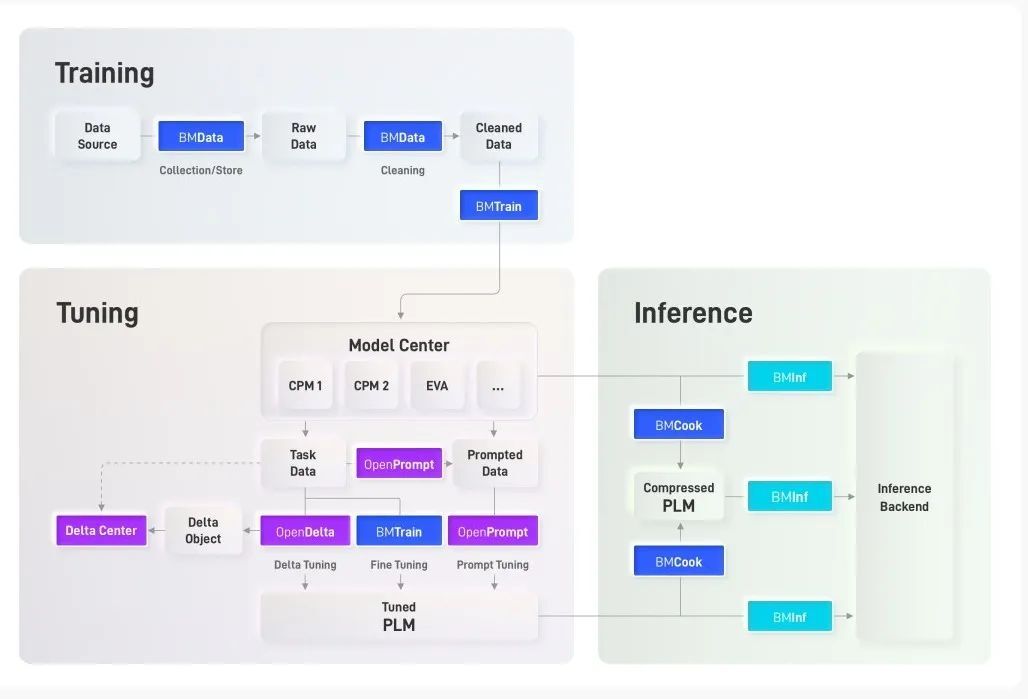
OpenBMB 工具架构图
模型训练套件
BMTrain:大模型训练“发动机”。BMTrain进行高效的大模型预训练与微调。与DeepSpeed等框架相比,BMTrain训练模型成本可节省90%。
开源地址如下:
https://git.openi.org.cn/OpenBMB/BMTrain
BMCook:大模型“瘦身”工具库。BMCook进行大模型高效压缩,提高运行效率。通过量化、剪枝、蒸馏、专家化等算法组合,可保持原模型90%+效果,模型推理加速10倍。
开源地址如下:
https://git.openi.org.cn/OpenBMB/BMCook
BMData:大模型“原料”收集器。BMData进行高质量数据清洗、处理与存储,为大模型训练提供全面、综合的数据支持。
模型微调套件
OpenPrompt:大模型提示学习利器。OpenPrompt提供统一接口的提示学习模板语言,2021年发布以来在国外某开源社区获得1.3k星标,每周访问量10k+。
OpenDelta:“小”参数撬动“大”模型。OpenDelta进行参数高效的大模型微调,仅更新极少参数(小于5%)即可达到全参数微调的效果。
Delta Center:“人人为我,我为人人” - Delta Object分享中心。Delta Center提供Delta Object的上传、分享、检索、下载功能,鼓励社区开发者共享大模型能力。
模型推理套件
BMInf:千元级显卡玩转大模型推理。BMInf实现大模型低成本高效推理计算,使用单块千元级显卡(GTX 1060)即可进行百亿参数大模型推理。2021年发布以来在国外某开源社区获得200+星标。
开源地址如下:
https://git.openi.org.cn/OpenBMB/BMInf
近期,OpenBMB开源社区已将部分完成开发的推理套件BMInf、训练套件BMCook和BMTrain上传与开源至OpenI启智社区,而后续也会将全部工具开源上来。未来,OpenBMB将依托自有开源社区和OpenI启智社区开源的力量,与广大开发者一道共同打磨和完善大模型相关工具,助力大模型应用与落地。期待广大开发者关注和贡献OpenBMB!
OpenBMB开源社区由清华大学自然语言处理实验室和智源研究院语言大模型加速技术创新中心共同支持发起。
发起团队拥有深厚的自然语言处理和预训练模型研究基础,曾最早提出知识指导的预训练模型ERNIE并发表在自然语言处理顶级国际会议ACL 2019上,累计被引超过600次,被学术界公认为融合知识的预训练语言模型的代表方法,被美国国家医学院院士团队用于研制医学诊断领域的自动问答系统;团队依托智源研究院研发的“悟道·文源”中文大规模预训练语言模型CPM-1、CPM-2,参数量最高达到1980亿,在众多下游任务中取得优异性能;团队近年来围绕模型预训练、提示学习、模型压缩技术等方面在顶级国际会议上发表了数十篇高水平论文,2022年面向生物医学的预训练模型KV-PLM发表在著名综合类期刊Nature Communications上,并入选该刊亮点推荐文章,相关论文列表详见文末。
团队还有丰富的自然语言处理技术的开源经验,发布了OpenKE、OpenNRE、OpenNE等一系列有世界影响力的工具包,在GitHub上累计获得超过5.8万星标,位列全球机构第148位,曾获教育部自然科学一等奖、中国中文信息学会钱伟长中文信息处理科学技术奖一等奖等成果奖励。
发起团队面向OpenBMB开源社区研制发布的BMInf、OpenPrompt、OpenDelta等工具包已陆续发表在自然语言处理顶级国际会议ACL 2022上。
OpenBMB主要发起人介绍
孙茂松
清华大学计算机系教授,智源研究院自然语言处理方向首席科学家,清华大学人工智能研究院常务副院长,清华大学计算机学位评定分委员会主席,欧洲科学院外籍院士。主要研究方向为自然语言处理、人工智能、社会人文计算和计算教育学。在人工智能领域的著名国际期刊和会议发表相关论文400余篇,Google Scholar统计引用超过2万次。曾获全国优秀科技工作者、教育部自然科学一等奖、中国中文信息学会钱伟长中文信息处理科学技术奖一等奖,享受国务院政府特殊津贴。
刘知远
清华大学计算机系副教授,智源青年科学家。主要研究方向为自然语言处理、知识图谱和社会计算。在人工智能领域著名国际期刊和会议发表相关论文200余篇,Google Scholar统计引用超过2万次。曾获教育部自然科学一等奖(第2完成人)、中国中文信息学会钱伟长中文信息处理科学技术奖一等奖(第2完成人)、中国中文信息学会汉王青年创新奖,入选国家青年人才计划、2020年Elsevier中国高被引学者、《麻省理工科技评论》中国区35岁以下科技创新35人榜单、中国科协青年人才托举工程。
韩旭
清华大学计算机系博士生,研究方向为自然语言处理、预训练语言模型和知识计算,在人工智能领域著名国际期刊和会议ACL、EMNLP上发表多篇论文,悟道·文源中文预训练模型团队骨干成员,CPM-1、CPM-2、ERNIE的主要作者之一。曾获2011年全国青少年信息学竞赛金牌(全国40人)、国家奖学金、清华大学“蒋南翔”奖学金、清华大学“钟士模”奖学金、微软学者奖学金(亚洲12人)、清华大学优良毕业生等荣誉。
曾国洋
清华大学计算机系毕业生,智源研究院语言大模型加速技术创新中心副主任。拥有丰富人工智能项目开发与管理经验,悟道·文源中文预训练模型团队骨干成员,BMTrain、BMInf的主要作者之一。曾获2015年全国青少年信息学竞赛金牌(全国50人)、亚太地区信息学竞赛金牌、清华大学挑战杯一等奖、首都大学生挑战杯一等奖。
丁宁
清华大学计算机系博士生,研究方向为机器学习、预训练语言模型和知识计算,在人工智能领域著名国际期刊和会议ICLR、ACL、EMNLP上发表多篇论文,悟道·文源中文预训练模型团队骨干成员,OpenPrompt、OpenDelta的主要作者之一。曾获国家奖学金、清华大学“清峰”奖学金、百度奖学金(全国10人)等荣誉。
张正彦
清华大学计算机系博士生,研究方向为自然语言处理和预训练语言模型,在人工智能领域著名国际期刊和会议ACL、EMNLP、TKDE上发表多篇论文,悟道·文源中文预训练模型团队骨干成员,CPM-1、CPM-2、ERNIE的主要作者之一。曾获国家奖学金、清华大学优良毕业生、清华大学优秀本科毕业论文等荣誉。
结语
OpenI启智社区是以鹏城云脑科学装置及软件开发群智范式为基础,由新一代人工智能产业技术创新战略联盟(AITISA)组织产学研用协作共建共享的开源平台与社区。
无论你正在从事大模型研究,研发大模型应用,还是对大模型技术充满兴趣,欢迎来OpenI启智社区使用OpenBMB开源工具和模型库。OpenBMB开源社区推崇简捷,追求极致,相信数据与模型的力量。欢迎志同道合的你加入,共同为大模型应用落地添砖加瓦,早日让大模型飞入千家万户。
OpenBMB相关链接
▶ 开源主页:
https://git.openi.org.cn/OpenBMB
▶ 官方网站:
https://www.openbmb.org
▶ 交流QQ群:
735930538
▶ 微博:
http://weibo.cn/OpenBMB
▶ 邮箱:
openbmb@gmail.com
▶ 知乎:
https://www.zhihu.com/people/OpenBMB
▶ Twitter:
https://twitter.com/OpenBMB
附录 团队论文发布列表
1. Zhengyan Zhang, Xu Han, Zhiyuan Liu et al. ERNIE: Enhanced Language Representation with Informative Entities. ACL 2019.
2. Xiaozhi Wang, Tianyu Gao, Zhaocheng Zhu et al. KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation. TACL 2021.
3. Yujia Qin, Yankai Lin, Ryuichi Takanobu et al. ERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive Learning. ACL-IJCNLP 2021.
4. Xu Han, Zhengyan Zhang, Ning Ding et al. Pre-Trained Models: Past, Present and Future. AI Open 2021.
5. Zhengyan Zhang, Xu Han, Hao Zhou et al. CPM: A Large-scale Generative Chinese Pre-trained Language Model. AI Open 2021.
6. Zheni Zeng, Yuan Yao, Zhiyuan Liu, Maosong Sun. A Deep-learning System Bridging Molecule Structure and Biomedical Text with Comprehension Comparable to Human Professionals. Nature Communications 2022.
7. Ning Ding, Yujia Qin, Guang Yang et al. Delta Tuning: A Comprehensive Study of Parameter Efficient Methods for Pre-trained Language Models. Arxiv 2022.
8. Zhengyan Zhang, Yuxian Gu, Xu Han et al. CPM-2: Large-scale Cost-effective Pre-trained Language Models. AI Open 2022.
9. Ganqu Cui, Shengding Hu, Ning Ding et al. Prototypical Verbalizer for Prompt-based Few-shot Tuning. ACL 2022.
10. Shengding Hu, Ning Ding, Huadong Wang et al. Knowledgeable Prompt-tuning: Incorporating Knowledge into Prompt Verbalizer for Text Classification. ACL 2022.
11. Yujia Qin, Jiajie Zhang, Yankai Lin et al. ELLE: Efficient Lifelong Pre-training for Emerging Data. Findings of ACL 2022.
12. Yuan Yao, Bowen Dong, Ao Zhang et al. Prompt Tuning for Discriminative Pre-trained Language Models. Findings of ACL 2022.
13. Ning Ding, Shengding Hu, Weilin Zhao et al. OpenPrompt: An Open-source Framework for Prompt-learning. ACL 2022 Demo.
14. Han Xu, Guoyang Zeng, Weilin Zhao et al. BMInf: An Efficient Toolkit for Big Model Inference and Tuning. ACL 2022 Demo.