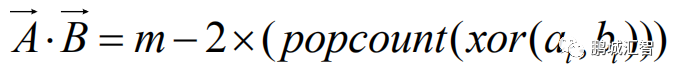PhoneBit: 基于手机 GPU 的高能效二值神经网络加速引擎开源项目发布
在过去的几年里,深度神经网络(DNN)已经在计算机视觉和其他领域取得了巨大的进展。然而,由于深度神经网络较高的计算复杂度,以及移动设备性能和功率限制,导致深度神经网络在移动设备上部署仍然具有挑战性。二值神经网络(Binary Neural Networks)是一种特殊的神经网络,它将网络的权重和中间特征压缩为 1 个比特位,通过使用位运算替代传统的浮点运算来实现模型的压缩与加速。现有的大多数神经网络计算框架,如MXNet、Caffe、TensorFlow等,它们大多为浮点计算框架,并只针对桌面平台的独立GPU优化。相比桌面与服务器独立GPU,移动端GPU往往与CPU合并在一块芯片上作为SoC的一部分,同时存在着功率小、可分配资源少、带宽低等限制,这使得在移动端GPU上进行并行计算的优化与独立GPU有很大的不同。而在移动设备上,大多数轻量级框架如TensorFlow Lite,CNNdroid,Core ML,Caffe2等,它们大多支持浮点与8bit量化,并不支持BNN,同时存在一定兼容性问题,如TensorFlow Lite对移动GPU的支持并不完善。2019年8月,京东AI开源了第一个基于ARM CPU的高度优化的BNN前向传播计算框架daBNN,但是daBNN使用CPU计算使得daBNN和其他使用CPU计算的框架一样,仍然具有在运算时发热大、消耗电量快等缺点。因此,使用移动GPU对BNN进行推理计算优化仍然是一个空白。
中山大学无人系统研究所陈刚副教授和黄凯教授联合鹏城实验室发表在DATE 2020的论文 《PhoneBit: Efficient GPU-Accelerated Binary Neural Network Inference Engine for Mobile Phones》提出了业界首个基于手机 GPU 的高能效二值神经网络加速引擎,针对移动端GPU进行高度优化。PhoneBit框架在进行二值神经网络推理的同时,可大幅提升推理速度,降低计算消耗的电量以及带来更高的能耗比。目前,PhoneBit框架已在鹏城汇智开源代码托管平台上正式发布(地址:
https://code.ihub.org.cn/projects/915)。
PhoneBit框架及其优化简介
如下图所示,PhoneBit框架加载一个在其他框架上训练好的模型,模型经过转换工具的转换后,上传至移动设备,只需要简单几步即可完成模型的部署。
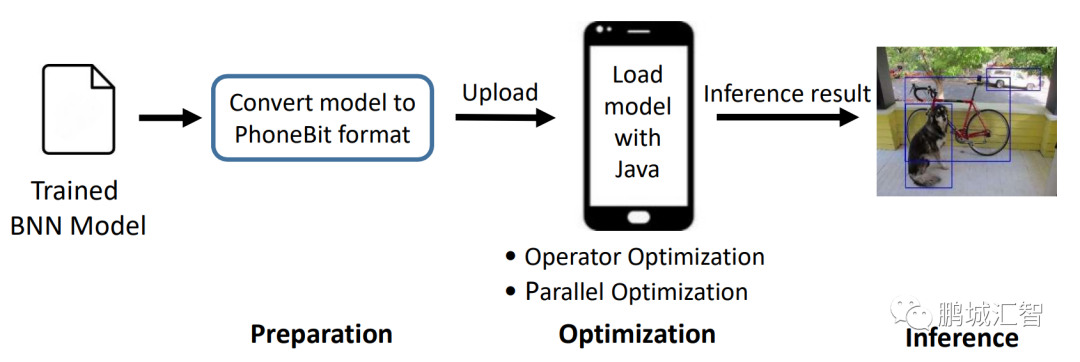
PhoneBit框架于移动端快捷部署BNN模型
同时,PhoneBit框架为使用者提供了多项支持:
1) 提供了对多种常用神经网络层的支持,例如add,convolution,max pooling,average pooling,BN,dense,softmax等层,同时支持shortcut结构并有对应的优化,理论上可适应大多数网络结构。
2) 支持混合精度,支持32位浮点,16位浮点,int8整数,二值化等计算方式。
3)提供了模型转换工具,支持从ONNX(Open Neural Network Exchange)模型转换至本框架专用模型,在转换模型的同时进行针对BNN的模型压缩与半精度浮点格式的转换,。
4) 考虑到Android应用大多采用Java编写,本框架提供了方便的Java API支持,使用者只需要简单的调用几行Java代码,即可自动实现模型的GPU推理计算。

使用框架进行BNN模型加载与推理
在BNN前向计算过程中,由于输入特征与权重只包含1与-1两种值,因此一个输入特征和权重可以只用1个二进制位来表示,而通常的输入特征与权重是浮点数,一个浮点数需要使用32个二进制位来表示,二者相差32倍,因此,BNN相比通常的浮点DNN,理论上可以将模型缩小32倍,同时计算上提升32倍的速度。在计算卷积层时,有大量的向量点乘操作。在BNN中,通过数学推导,传统的浮点向量点乘操作可以被以下公式替代:
其中,
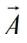
与

是由浮点向量经过压缩后的二值向量,
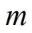
是向量的长度,
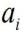
与
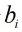
分别是
、
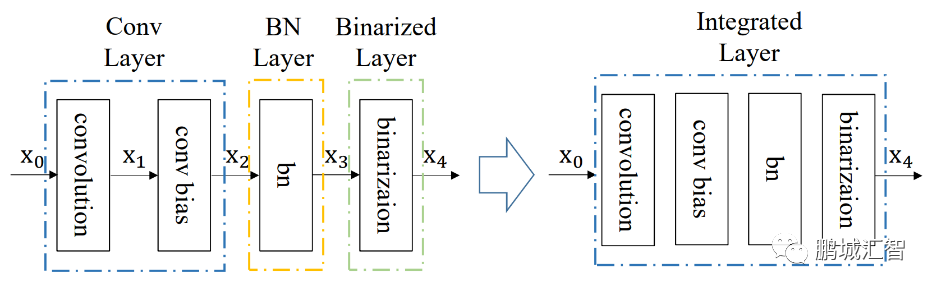
中每个比特位。因此,在BNN中的卷积计算时采用上述公式,就能完成使用1位二进制位计算代替通常的32位计算,极大的减小了传输的数据量与计算量。同时,在BNN计算中将卷积层、Batch-Normalization(BN)层、二值化层(将浮点数据变为1与-1的层)整合,通过层与层之间的整合,层之间额外的数据传输以及计算量得到大幅度降低,从而节省时间。
同时,针对移动GPU的体系结构,PhoneBit框架采用了向量化访存与计算、合并内存访问、隐藏访存延迟、合理安排计算量负载、避免逻辑分支的判断等计算优化方法。相比于矢量方式1次指令只能读取1个数据,向量化方式读写使得计算时GPU可以只使用1次指令即可读取若干个数据如4个、8个甚至16个,达到高效利用内存带宽的效果;合并内存访问则是将GPU中同一批计算单元安排处理内存上连续的数据,这样访存时不需要间隔访问,达到最大的读写率;隐藏访存延迟则通过安排GPU中一批计算单元计算时,另一批待计算的单元同时读取数据,避免相互等待;合理安排计算量负载则是根据计算规模的不同,调整GPU同一批计算单元进行计算的数据量,使之不会因为计算数据量过少而造成浪费,也不会因为数据量过多造成拥塞。避免逻辑分支则是尽可能让GPU中同一批计算单元执行相同的条件分支代码,节省执行时间。通过以上优化方法,PhoneBit框架速度比较如下:
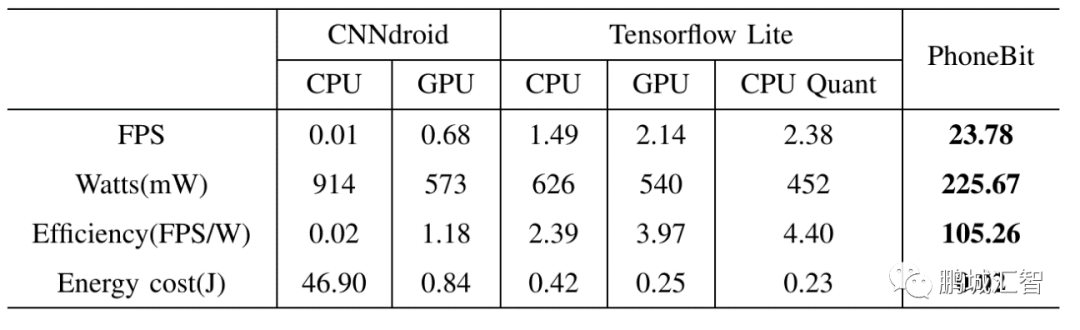
于高通骁龙820平台运行YOLOv2 Tiny网络与现有主流浮点DNN框架对比
在高通骁龙820平台,运行YOLOv2 Tiny网络,相比CNNdroid(一个基于Android RenderScript的浮点神经网络前向传播框架),PhoneBit框架实现了1218-2378倍的速度提升,2.54-4.05倍更低的功率以及89-5263倍更高的能效比。相比TensorFlow Lite(谷歌针对移动设备提出的轻量级神经网络前向传播框架,支持浮点与8bit量化模式),PhoneBit框架实现了10-15.6倍的速度提升,2-2.77倍更低的功率以及23.9-44倍更高的能效比。
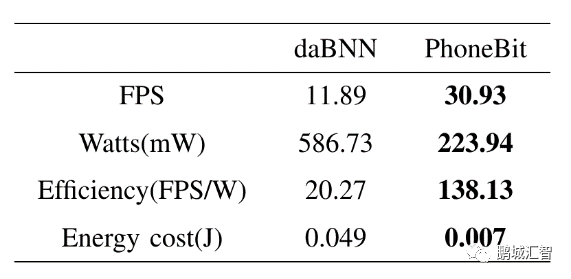
于高通骁龙820平台运行Bi-Real Net 18网络与现有基于ARM的BNN框架对比
在高通骁龙820平台,运行Bi-Real Net 18网络,相比daBNN(一个最新的基于ARM高度优化的二值神经网络框架),PhoneBit框架实现了2.6倍的速度提升,2.62倍更低的功率以及6.8倍更高的能效比。

PhoneBit框架使用Bi-Real Net 18网络对物品进行分类
目前,PhoneBit框架项目仍在不断快速迭代进化,框架整体性能亦在不断提升中,希望能够以此项目为相关领域的科研工作者、开发者们提供一个稳定易用、高效便捷的轻量化神经网络加速引擎。同时,也期望能有更多志同道合的朋友加入项目组,共同开发、优化本项目,为PhoneBit框架的发展出一份力。