跨出类脑芯片的关键一步,成立仅两年aiCTX有望先于IBM和Intel产业落地
科技巨头往往是前沿科技的引领者,在AI、5G、物联网逐步普及的当下,IBM、谷歌、微软、百度、阿里等国内外巨头都在投入巨大资源争抢新一轮科技浪潮的话语权。其中颠覆传统冯诺依曼架构,被誉为未来全新一代人工智能处理器的类脑芯片也引发了不少关注,IBM和Intel等都已发布类脑芯片,国内的华为、阿里、百度等巨头都在争相竞逐这个领域。类脑芯片是人类脑研究和半导体技术的全新结合,具有巨大的发展前景。
aiCTX,一家位于瑞士苏黎世,成立仅2年的初创公司,其类脑芯片产品将有望领先全球各巨头实现产业化落地?
AI、量子计算、类脑芯片都被不少人视作“黑科技”,但其实这些概念首次被提出都很早,类脑芯片或者说神经形态计算的概念,至少可以追溯到20世纪80年代,当时传奇的加州理工学院研究员Carver Mead提出设计集成电路来模仿活神经元细胞的组织。然而,由于生物神经元的发射是非确定性的,经典计算架构冯诺依曼是确定性的架构,这一因素在很大程度上让计算机无法模仿人类大脑。
除了技术的难题,类脑研究人员的心态也是一个重要影响。在类脑研究起步较早的欧洲,许多研究人员进行相关的研究是觉得类脑研究很有意义,并且很享受研究的过程,而不是考虑如何去应用或实现商业化。
业界也出现了对类脑芯片可行性的质疑。对此,aiCTX首席执行官乔宁博士表示:“因为看不到应用,出现质疑的声音很正常。我进入这一领域前是中科院半导体研究所博士,主要进行低功耗数模混合电路的设计。自2012年起加入苏黎世大学及苏黎世联邦理工大学的神经信息研究所INI进行类脑芯片研究,从12年到16年底,基本每年都会设计1-2款神经形态处理器,对类脑芯片有很深的理解。”
除了各高校及科研院所,可以观察到的是包括IBM、Intel等在内的科技巨头都在投入资金研发并陆续推出类脑芯片。
aiCTX首席执行官乔宁博士
近几年,美国DARPA投巨资支持IBM及Intel等美国巨头高科技公司开展TrueNorth及Loihi类脑芯片开发项目,并已经在多个领域得到应用。美国劳伦斯-利弗莫尔国家实验室、美国空军研究实验室(AFRL)也均购买过IBM的TrueNorth芯片。这也能说明研发类脑芯片的可行性以及重大的战略意义。
那么,研究开发类脑芯片的意义到底是什么?这就得从本质上去理解。神经形态装置(包含传感和处理等)的工程涉及开发其功能类似于大脑部分的组件。人脑的活体神经细胞有四个主要的功能成分,如下图所示:
- Synapses(突触):电化学脉冲通过称为突触的微小界面点进入细胞
- Dendrites(树突):突触分散在称为树突的树根状纤维的表面上
- Cell Body(细胞体):树突伸展到周围的神经组织,从突触中收集脉冲,并将脉冲传回神经元的心脏,称为细胞体。
- Axon(轴突):一种树状纤维,将细胞体的输出脉冲传导到神经组织,最终在其他细胞的树突上突触。
在生物大脑中,每个神经元都与各种输入相连。一些输入在神经元中产生激发,而另一些输入则抑制它,如人工神经网络中的正负权重。但对于SNN(脉冲神经网络),在达到由变量(或者可能具有函数)描述的特定阈值状态时,神经元发出脉冲信号。正是由于这种特性,只有当神经元脉冲观察到域的变化时,神经形态系统才需要能量,所以这种系统相比冯诺依曼计算机有显著的功耗优势以及更强的自适应学习能力。
大脑的神奇之处在于实时处理复杂信息的同时只消耗极少的能量。而神经拟态工程的目标不是模仿大脑,而是理解大脑如此高效的工作机制,并把这些机制用到的芯片中去。这些机制中,细粒度并行计算,神经动力学,时域编码,基于时间的信息处理等等,直接启发了新特征,新架构,新算法对计算系统的能力以及效率的突破。
正如Intel前不久发表声明指出,脉冲神经网络是目前深度神经网络的必然继承者,脉冲神经网络在运算中利用了时域动力学,因此非常适合于实时处理真实世界的传感器数据,例如声音或者视频,尤其是在需要快速实时响应的情况下。
从算法角度看,脉冲神经元提供了可以在时间域进行实时信息处理的神经网络的基本方法。从硬件实现角度看,类脑架构可以利用脉冲机制进行高度稀疏的脉冲驱动运算,大大节省了能耗。所有这些优势对边缘计算在能效和实时性上有极大的提升,尤其是边缘设备需要对实施动态数据的实时本地处理,比如生产车间,自动驾驶汽车或者机器人等。
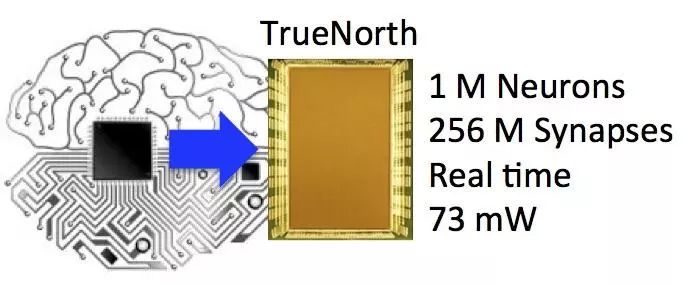
可以看到,2011年8月IBM率先研发出具有感知、认知功能的脉冲神经网络芯片原型,推出第一代TrueNorth。到了2014年,TrueNorth第二代诞生,功耗为每平方厘米20毫瓦,是第一代的百分之一。总体看,第二代TrueNorth芯片由4096 个内核,100 万个 “神经元”、2.56 亿个“突触”集成。
IBM当时表示如果 48 颗TrueNorth芯片组建起具有 4800 万个神经元的网络,带来的智力水平将相似于普通老鼠。但这款芯片亮相之后就没有大动作,也未应用到其人工智能系统Watson中。
到了2018年,Intel展示了耗时多年研发的其首款自学习脉冲神经元芯片Loihi。Intel称Loihi内部包含了128个计算核心,每个核心集成1024个人工神经元,总计13.1万个神经元,彼此之间通过1.3亿个突触相互连接。
即便如此,相比人脑内的800多亿个神经元的Loihi仍然相对简单。不过,Intel给出的数据指出,Loihi的学习效率比其他智能芯片高100万倍,而在完成同一个任务所消耗的能源可节省近1000倍。
与IBM一样,Intel类脑芯片发布之后也未见其有在产业端有进一步的消息。
之所以会出现这样的情况,
乔宁博士认为,无论是IBM还是Intel,他们目前对神经拟态智能(Neuromorphic Intelligence)或者说类脑芯片的投入更多聚焦在科研层面,针对的用户也大都是科研院所,并没有在商业应用方面做更多考虑。
与学校科研不同,公司层面最重要的还是技术与产品的落地。
乔宁博士强调,我们创立公司做类脑芯片从一开始就是以应用为主导,类脑芯片最擅长的是超低功耗的实时动态信息处理,针对的应用场景是IoT端的传感器信息的本地实时超低功耗处理。“目前aiCTX的类脑芯片按应用分为两大类:一类是针对动态视觉的处理器芯片。这类芯片是类脑与传统深度学习的结合体,在算法上依赖的是深度学习的CNN,而运算的触发机制则为脉冲触发。另一类是对有时间维度(语音,心电信号,肌电信号,温度压强等)的自然信号实时处理的脉冲神经网络处理器。这一类处理器在算法层面依赖的是神经动力学,依靠脉冲神经网络进行超低功耗实时动态传感器信息处理。”
当然,选择与研究机构和巨头不同的道路,以应用为驱动去设计类脑芯片自然还不足以超越他们,最关键的还是需要技术上的积累与突破。aiCTX背靠的是在神经拟态(neuromorphic)领域全球领先的苏黎世大学及苏黎世联邦理工大学神经信息研究所(Institute of Neuroinformatics,简称INI),有20多年成熟的脑科学,神经形态架构、算法、芯片等各方向的研发经验。据了解,该研究所于1995年由苏黎世联邦理工学院(ETH Zurich,2019年QS世界大学排名第7名)和苏黎世大学(UZH,2019年QS世界大学排名第78名)联合创办。
深耕科研,基于多年世界领先的科研成果,乔宁博士与业界大牛Giacomo Indiveri教授一起于2017年2月底在瑞士苏黎世创立类脑芯片公司aiCTX。乔宁博士告诉雷锋网,aiCTX = AI-CorTex,CTX是英文中Cortex(脑皮层)的缩写。aiCTX的名字与“脑皮层”紧密相连,代表aiCTX神经拟态运算在硬件中实现,以期解决人工智能中的问题。
乔宁博士表示:“从2012年起加入INI领导欧洲类脑芯片项目开发,我和团队已经成功研发多款aiCTX的核心研发团队在脉冲神经网络模型、算法、类脑芯片架构,芯片设计等领域拥有国际顶级学术文章500多篇,引用量达12000多次。”
事件驱动运算是脉冲神经网络的天然属性,而传统的深度学习很难做到这一点,这是实现脉冲神经网络的类脑芯片在超低功耗边缘运算上极大的优势。
乔宁博士认为,每个人对类脑芯片的理解和定义有所不同,但其最天然的属性是事件驱动运算。只有做到事件驱动运算,才可能实现真正意义上的“听着看着又不耗电”的适用于IoT的可以Alawys On边缘AI应用。
设计事件驱动或者说脉冲神经网络处理器时无法回避的就是脉冲的生成与传递是随机的,如果用时钟就会大大降低效率,也因为引入额外功耗很难做到Always On,
如果想做高效的脉冲神经网络处理器,异步电路必不可少。而设计异步电路时,由于没有很好的EDA软件支持,不能像设计传统数字电路那样借助EDA快速且方便的完成设计,因此异步电路设计对大部分公司而言这非常困难。
“我们从2012年就开始做基于异步电路的类脑芯片设计,并且发展了一整套内部的EDA软件支持我们完成异步电路的自动化设计与验证,这是很大的优势。”乔宁博士指出。
aiCTX DynapCNN
最终我们看到,aiCTX发布了世界首款完全基于事件触发运算的动态视觉AI处理器DynapCNN。该处理器是一款纯异步、高可配置性、可拓展性的神经形态处理器。芯片面积仅为12平方毫米,采用GF22nm工艺设计,单芯片集成超过100万脉冲神经元和400万可编程参数,支持多种CNN架构,其芯片架构所具有的可拓展性适合于实现大规模脉冲卷积神经网络。
并且,DynapCNN的高灵活性和可重新配置性也为开发和实现一系列AI模型提供了可能性,基于动态视觉的事件触发运算机制使得芯片达到亚mW级的功率。此外,芯片使用稀疏计算对场景中的物体移动进行处理,进一步降低了芯片的动态功耗。
另外,DynapCNN处理器集成专用接口电路,可直连绝大多数动态摄像头,进行脸部识别、手势识别、高速移动物体追踪、归类、行为识别等。
据介绍,DynapCNN可以对像素级动态数据流进行连续计算,对移动物体实时识别可实现低于5ms的超低延迟。
相较于已有的深度学习实时视觉处理方案,DynapCNN所提供的超低延时动态视觉解决方案对比与DL加速器技术,将识别响应延时缩短了10倍以上,同时功耗降低100倍以上,能为车载及高速飞行器等高速视觉场景提供更好的解决方案。乔宁博士表示,DynapCNN相应的开发套件将于2019年第三季度上市。
除了路线、技术与巨头的不同,能让aiCTX在商用方面取得领先的第三个关键就是产品模组化。乔宁博士在接受专访的时候也提到,
即便一个很完善的类眼DVS(Dynamic Vision Sensor ,动态视觉传感器),搭配传统CPU或者DL加速器进行动态视觉处理,效率也会大打折扣。新一代的神经拟态智能必须是完整的系统级的解决方案,才能发挥出最大的优势。
因此,aiCTX将在今年三季度将会推出首款整体功耗 <1mW的SoC级动态视觉智能传感器Speck。该芯片基于65nm工艺设计,片上集成动态摄像头及动态处理器。作为一个完整的动态视觉解决方案,Speck的整体峰值功耗将低于1mW;而在通常智能家居等应用场景下,整体平均功耗将在0.5mW以下 (1节5号电池可驱动近1年的时间)。对于轻量级的边缘视觉智能应用,使用者将不需要再添加额外的处理器或摄像头,即插即用。这样做无疑也是为了降低类脑芯片的使用门槛。
乔宁博士也表示,aiCTX的产品的应用也有一个短期、中期、长期的规划,
短期看视觉物联网的应用会更快。 对于动态信息实时处理的超低功耗,超低延时以及成本是我们方案的竞争力所在。现在公司与许多潜在客户都有接触,包括瑞士的IoT公司,国内的Tier1车企、AI芯片公司等,无论是项目层面还是产品层面,短期可能都会有一些合同达成。
另据雷锋网了解,为了满足车企的需求,aiCTX已经将车轨级认证的要求加入了下一代芯片设计的考量中,这也将是他们近期工作的重点之一。
aiCTX也得到了资本的认可,2017年底,获得十维资本领投的数百万美元天使轮融资。2018年底,获得BV(百度风投)领投的数百万美元Pre-A轮融资,用于加速研发及技术成果落地。2018年初,成功获批了欧盟H2020关于脑机接口的为期4年的科研项目“SYNCH”及欧盟动态机器视觉科研项目“TEMPO”,并获得相应经费支持。下一步,aiCTX计划于2019年6月完成A轮融资。
至此,从原理上看我们已经可以明确类脑芯片具备超低功耗和超低延时,更适合IoT边缘传感器的动态信息本地实时处理等优点。不仅如此,由于aiCTX的SNN处理器算力主要是用于稀疏点数据流的实时处理,因此并不强调算力。并且,对于先进工艺的需求也并不十分强烈。
乔宁表示:“类脑芯片对工艺的需求主要取决于应用,如果对于网络资源有较大的需求,比如用于无人车或者无人机超低延时动态视觉AI应用,才需要22nm等先进工艺;但是如果是语音识别或者心电信号检测,因为需要的硬件资源很小,只需要65nm甚至180nm的工艺,这也能在很大程度上降低成本。”
不过,对于目前的云端计算而言,并不适合类脑芯片。乔宁表示:“类脑芯片更擅长的是超低功耗动态信息实时处理,因此更适合用在端上。而比如传统摄像头生成的基于帧的静态数据,则更适合用传统的深度学习芯片处理。但以现在的趋势看,多传感器融合进行动态数据处理将是主要发展方向之一,类脑芯片未来也可在云加端发挥优势。”