百度 ERNIE 2.0强势发布!16项中英文任务表现超越 BERT 和 XLNet
2019年3月,百度正式发布 NLP 模型 ERNIE,其在中文任务中全面超越 BERT 一度引发业界广泛关注和探讨。
今天,经过短短几个月时间,百度 ERNIE 再升级。发布持续学习的语义理解框架 ERNIE 2.0,及基于此框架的 ERNIE 2.0预训练模型。继1.0后,ERNIE 英文任务方面取得全新突破,在共计16个中英文任务上超越了 BERT 和 XLNet, 取得了 SOTA 效果。
目前,百度 ERNIE 2.0的 Fine-tuning 代码和英文预训练模型已开源。( Github 项目地址:https://github.com/PaddlePaddle/ERNIE)
近两年,
以 BERT 、 XLNet 为代表的无监督预训练技术在语言推断、语义相似度、命名实体识别、情感分析等多个自然语言处理任务上取得了技术突破。基于大规模数据的无监督预训练技术在自然语言处理领域变得至关重要。
百度发现,之前的工作主要通过词或句子的共现信号,构建语言模型任务进行模型预训练。例如,BERT 通过掩码语言模型和下一句预测任务进行预训练。XLNet 构建了全排列的语言模型,并通过自回归的方式进行预训练。
然而,
除了语言共现信息之外,语料中还包含词法、语法、语义等更多有价值的信息。例如,人名、地名、机构名等词语概念知识,句子间顺序和距离关系等结构知识,文本语义相似度和语言逻辑关系等语义知识。设想如果能持续地学习各类任务,模型的效果能否进一步提升?
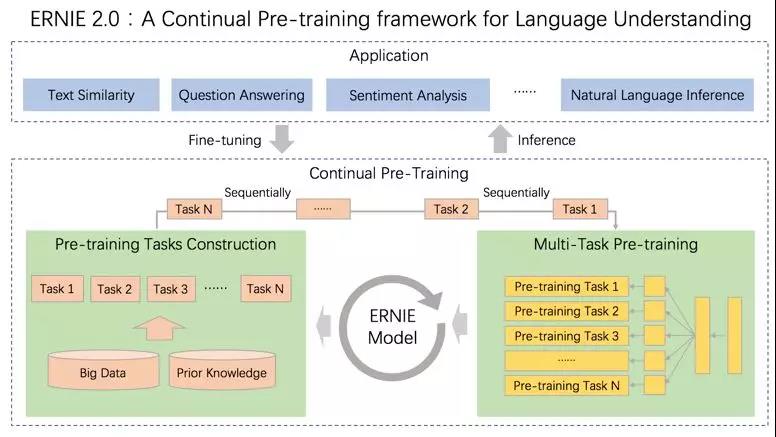
▲ERNIE 2.0:可持续学习语义理解框架
基于此,百度提出可持续学习语义理解框架 ERNIE 2.0。该框架支持增量引入
词汇( lexical )、语法 ( syntactic ) 、语义( semantic )等3个层次的自定义预训练任务,能够
全面捕捉训练语料中的词法、语法、语义等潜在信息。
这些任务通过多任务学习对模型进行训练更新,每当引入新任务时,该框架可在学习该任务的同时,不遗忘之前学到过的信息。这也意味着,该框架可以通过持续构建训练包含词法、句法、语义等预训练任务,持续提升模型效果。
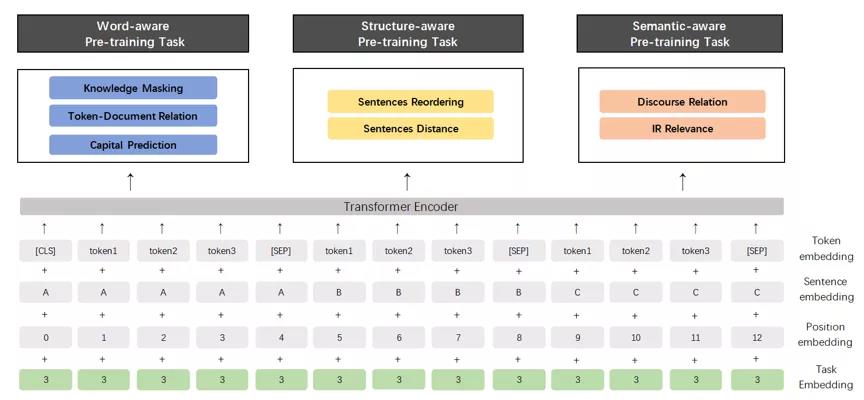
▲新发布的 ERNIE 2.0模型结构
依托该框架,百度充分借助飞桨 PaddlePaddle 多机分布式训练优势,利用 79亿 tokens 训练数据(约1/4的 XLNet 数据)和64张 V100(约1/8的 XLNet 硬件算力)训练的
ERNIE 2.0预训练模型不仅实现了 SOTA 效果,而且为开发人员定制自己的 NLP 模型提供了方案。目前,百度开源了 ERNIE 2.0的 Fine-tuning 代码和英文预训练模型。
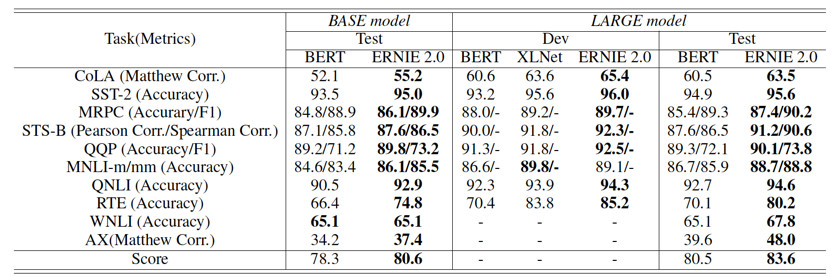
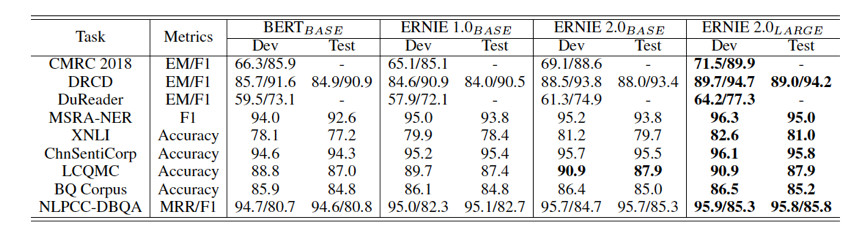
百度研究团队分别比较了中英文环境上的模型效果。英文上,ERNIE 2.0在自然语言理解数据集 GLUE 的7个任务上击败了 BERT 和 XLNet。中文上,在包括阅读理解、情感分析、问答等不同类型的9个数据集上超越了 BERT 并刷新了 SOTA。
ERNIE 的工作表明,在预训练过程中,通过构建各层面的无监督预训练任务,模型效果也会显著提升。未来,研究者们可沿着该思路构建更多的任务提升效果。
自2018 年预训练语言模型 BERT 提出之后,预训练语言模型将自然语言处理的大部分任务水平提高了一个等级,这个领域的研究也掀起了热潮。如今可持续学习的特点亦将成为 NLP 领域发展里程中的关键。
来源 | 百度AI